无人机没有IMU还能竞速飞行?苏黎世大学团队现场演示!
2025年3月,在苏黎世Kaufleuten剧院的WorldMinds大会上,500 多名现场观众见证了两架完全依赖视觉的自主竞速无人机在舞台间穿梭。背景大屏实时可视化每架无人机AI算法的观测与决策,而整套系统没有地图、没有惯性测量单元(IMU)、没有传统 SLAM,并且在昏暗灯光与严格安全限制下仍能稳定飞行。
这场表演凝聚了苏黎世大学机器人与感知研究组(RPG)多年来针对AI无人机研究的一系列关键技术成果,标志着他们在纯视觉自主飞行领域的重大里程碑。本文将带您梳理这些研究脉络,剖析关键技术,展望未来应用前景。
01
Swift:AI战胜世界冠军
当算法把每一次俯冲、翻滚都算得比人类更准、更快时,冠军飞手也只能望“机”兴叹。2023年苏黎世大学RPG团队联合英特尔团队设计了一种自主无人机系统—Swift,并在正式比赛中击败了3名世界冠军级别的人类无人机竞速飞手,总战绩为15胜10负,并打破了最快无人机竞速记录。这一重磅研究成果,也以封面文章的形式发表在了当期的 Nature 杂志上。
技术亮点
只用机载视觉+IMU,完全摆脱外部定位与 SLAM 依赖,信息条件达到与人类飞手一致。
仅需50 秒实飞数据,即可用高斯过程+KNN 快速补偿感知和动力学误差,实现零样本迁移。
感知-控制两阶段实现端到端强化学习策略。
奖励函数兼顾速度与视场,把“相机对准赛门”写进奖励,确保高速下仍稳准通过。
高保真并行仿真,50 分钟训练1e8 步,精确复刻 PID、ESC 与电池模型,大幅缩短迭代周期。
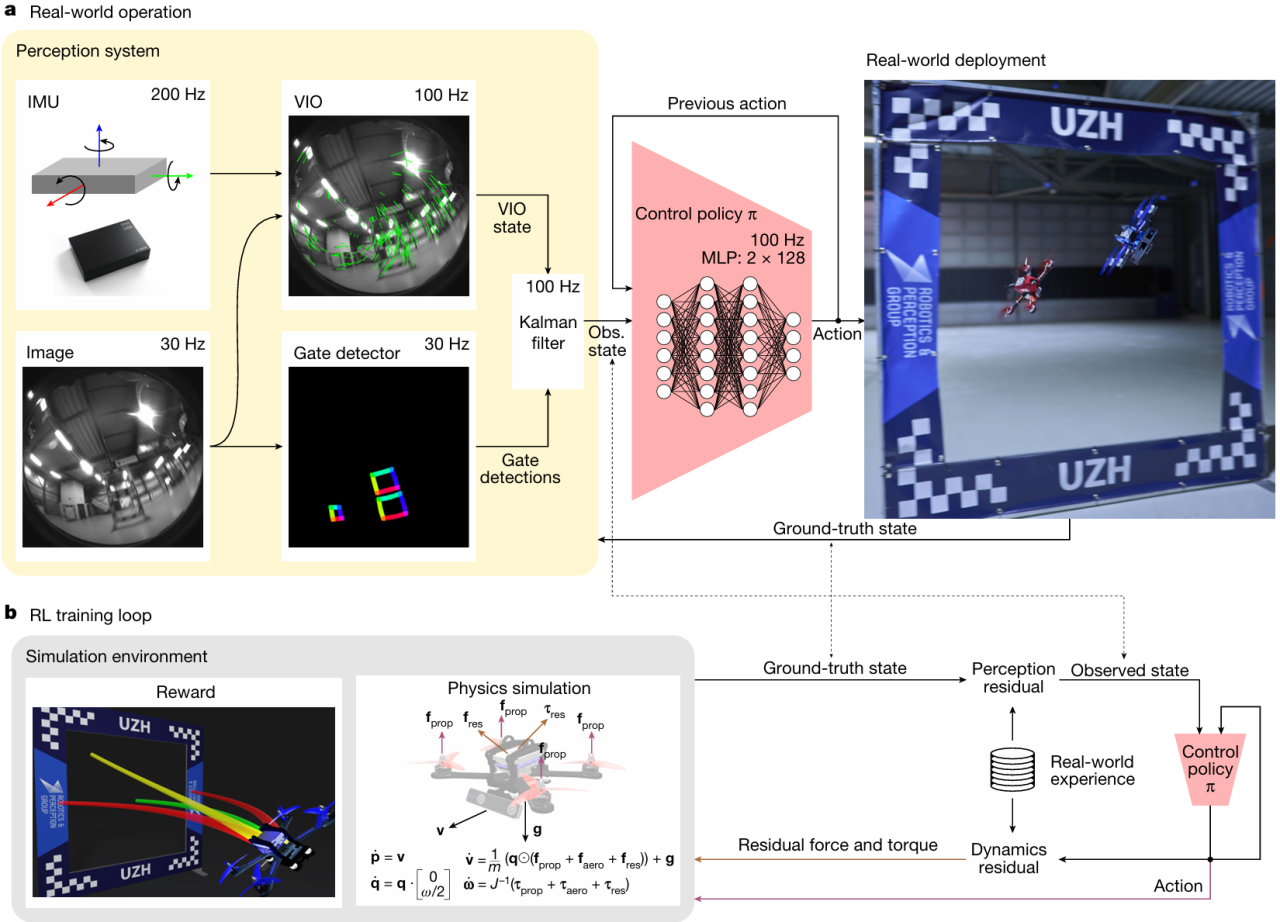
图片来源于论文《Champion-level Drone Racing Using Deep Reinforcement Learning》,Elia Kaufmann 等,Nature 2023
02
强化学习优于最优控制
2023年9月苏黎世大学RPG团队在《Science Robotics》发表的研究中,比较了强化学习和最优控制在无人机竞速中的表现。结果显示,强化学习在面对复杂环境和模型不确定性时,能够直接优化任务级目标,展现出更强的适应性和性能。

三种控制方案对比
Trajectory Tracking:离线求最短时轨迹,在线 MPC 跟踪。
Contouring Control:在线 MPC 同时最大化路径进度并最小化偏差。
Gate-Progress RL:端到端 RL 直接最大化朝下一赛门中心的位移,无需参考轨迹。
主要结论
优化方法并非决定因素,优化目标是关键。
证明在高动态机器人任务中,选择恰当的优化目标可让强化学习( RL) 超越最优控制。
- 下一步需摆脱外部 VICON、提升对环境变化和碰撞后的恢复能力。
03
端到端视觉飞行控制
在专业无人机竞速中,人类飞手只依靠第一视角(FPV)视频流即可完成高速穿门;而学术界最“敏捷”的自主四旋翼,仍离不开 VIO/SLAM 的显式状态估计。2024年苏黎世大学RPG团队首次在真实环境中验证—完全不依赖 IMU 与状态估计,仅凭视觉也能以 40 km/h、2 g加速度完成三圈竞速。

图片来源于论文《Demonstrating Agile Flight from Pixels without State Estimation》,Ismail Geles等,Robotics:Science and Systems 2024
技术亮点
视觉特征驱动控制:首次实现基于摄像头视觉特征(而非状态估计)直接生成推力和角速度指令,摆脱了IMU和SLAM依赖。
门框内缘抽象建模:提出使用门框内缘特征作为视觉输入,高效仿真训练、加速强化学习过程。
不对称Actor-Critic架构:训练过程中引入特权信息指导Critic,提升从视觉输入学习复杂控制策略的样本效率与稳定性。
Swin Transformer视觉感知器:开发基于Swin Transformer V2的高鲁棒性门检测器,应对实际环境下光照、模糊等挑战。
零状态估计下真实部署:在真实世界中,以100\%成功率完成高速飞行任务,验证了从仿真到现实的直接迁移能力。
04
让环境也会“思考”
过去几年,强化学习(RL)已经在机器人控制领域取得了巨大成功,从灵巧操作、四足奔跑,到高动态无人机竞速。但一个关键问题仍未解决:RL代理一旦换了新环境(比如赛道布局变化),就几乎无法适应,必须重训,这极大地限制了其实际应用。今年苏黎世大学RPG团队在ICRA会议提出通过引入一个环境策略(Environment Policy),动态调整赛道布局,系统可以培养出一个能在各种陌生赛道上飞行的通用无人机策略,无需每次重新训练。
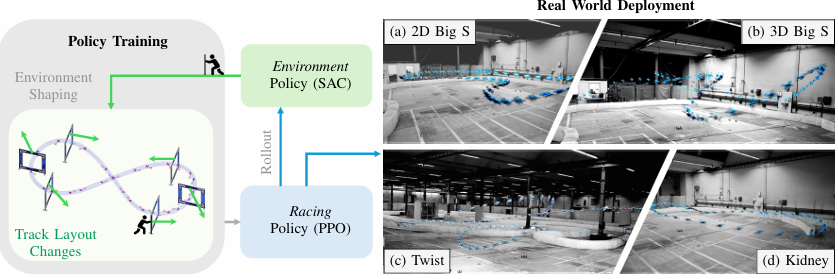
图片来源:论文《Environment as Policy: Learning to Race in Unseen Tracks》,Hongze Wang 等,ICRA 2025
技术亮点
环境适应策略引入:首次在无人机竞速中引入基于强化学习的环境策略(SAC),动态塑造训练赛道,指导飞行策略成长。
相对排名奖励机制:环境策略的奖励设计基于飞行策略在不同赛道中的相对表现,自动平衡赛道的难易程度。
单一飞行策略通吃多种未知赛道:训练出的单一策略无需重训,即可在6种复杂2D与3D未见赛道中以100\%成功率完成飞行。
动态赛道飞行测试:在移动门洞赛道上,飞行策略展现出远超传统方法的适应性,能应对大幅动态扰动。
真实世界迁移验证:在真实物理无人机平台上直接部署,成功完成所有未见赛道的飞行任务,验证了仿真到现实的通用迁移能力。
05
AI无人机的未来已来
应用前景
工业巡检与维护:无需安装外部定位设备、可在复杂管廊与核电站等受限环境中高效飞行。
搜救与紧急响应:轻量级纯视觉系统,适合夜间或烟雾等低能见度场景,实现快速自动化搜索。
智慧物流与城市空中交通:规模化部署更经济,支持多样化航线自适应规划与鲁棒飞行。
影视航拍与赛事直播:精准追踪与高动态画面捕捉,带来更具冲击力的影像体验。
资源速递
基于深度强化学习的冠军级无人机竞速
Champion-level Drone Racing Using Deep _Reinforcement Learning
论文链接:_https://www.nature.com/articles/s41586-023-06419-4.pdf
挑战极限:自主竞速中最优控制与强化学习对比研究
Reaching the Limit in Autonomous Racing: Optimal Control versus Reinforcement Learning_
论文链接:_https://www.science.org/doi/10.1126/scirobotics.adg1462
无需状态估计的视觉驱动敏捷飞行
Demonstrating Agile Flight from Pixels without State Estimation_
论文链接:_https://rpg.ifi.uzh.ch/docs/RSS24\_Geles.pdf
基于视觉的敏捷飞行中,通过模仿学习助力强化学习
Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight_
论文链接:_https://rpg.ifi.uzh.ch/docs/CoRL24\_Xing.pdf
四旋翼的多任务强化学习方法
Multi-Task Reinforcement Learning for Quadrotors
_论文链接:_https://rpg.ifi.uzh.ch/docs/RAL24\_Xing.pdf
以环境为策略:学习在未知赛道上自主竞速
Environment as Policy: Learning to Race in Unseen Tracks论文链接: https://rpg.ifi.uzh.ch/docs/ICRA25\_Wang.pdf
关注阿木实验室,更多技术干货不断更新!
开发遇到棘手难题可以上阿木官方论坛:
**bbs.amovlab.com
**有工程师亲自解答10000+无人机开发者和你共同进步!


